
Can $1.5B Sarvam be India’s Intelligence Infrastructure?
Customer
Profile
Series B-D
Last fortnight, Bangalore-based Sarvam AI raised $350 million at a $1.5 billion valuation, with it being India's largest-ever private funding round for a pure-play AI company
The Volunteers
Sometime around 2011, a chip design engineer named Vivek Raghavan made a decision that made little financial sense.
He had an IIT Delhi degree, a PhD from Carnegie Mellon, and a vice president role at Magma Design Automation. He had every reason to stay on that track. Instead, he walked into the Unique Identification Authority of India and offered to help build Aadhaar's biometric systems. For free. The conviction was simple - India needed the infrastructure, and someone had to build it.
He stayed for twelve years without a meaningful salary.
While Raghavan was helping enrol a billion Indians into a digital identity system, the world said could not be built at that scale, Pratyush Kumar was doing research in Big Tech. An IIT Bombay graduate who had taken his PhD to ETH Zurich and then spent years at IBM and Microsoft Research, Kumar was building a career in the kind of AI research that seldom made headlines. It was painstaking, unglamorous work in natural language processing for a country whose languages the global field had largely deemed not worth the trouble.
By 2012, the field's position on Indian languages was not a policy but an unfortunate economic reality. The data did not exist at scale, the speakers were not yet the users the industry was building for, and the researchers who cared about this were mostly working at non-profits and academic labs on budgets that would not cover a month of GPU time at a frontier Western lab. Without resources or deep pockets backing him, Kumar kept going. Built the datasets and benchmarks that proved the gap existed, on the assumption that someone would eventually care enough to close it.
One man was building biometric rails for a billion people without taking a rupee for it. The other was writing papers about a language problem the industry had not yet decided was worth solving. Different work, but it shared the same underlying conviction. India's digital future could not be borrowed from elsewhere and had to be built from within.
Neither knew that the world would soon prove them right, while barely noticing the work that had made the moment possible.
Alexa, Say Something in Telugu
In 2014, Amazon launched Alexa. In 2016, Google Assistant arrived. Siri had been around since 2011.
Each was a small miracle of engineering: impressive, useful, and still unsuited to a country where hundreds of millions spoke Hindi, Telugu, Tamil, Marathi, Bengali, and many other languages. Each of these languages individually had more speakers than the largest European countries, yet no one was building for them.
People tried asking Alexa something in Kannada. Or Siri to help your grandmother navigate an Odia government form. What they would get back is the AI equivalent of a tourist reading from a phrasebook: technically functional, culturally alien, and missing the texture of how people speak. The models were trained overwhelmingly on English books, English websites, and English conversations, and then asked to perform in languages for which they had seen a fraction of the data.
The problem was not translation alone. The architecture itself was built for another language. Global models were trained mostly on English data, broken into tokens optimised for English, and priced around users whose economics looked nothing like India's. By 2018, it was clear that nothing was really working well for almost all Indian languages.
You could argue, and Pratyush Kumar would later publish papers arguing this, that the entire AI revolution of the 2010s was built on a dataset representing around 10% of humanity and then deployed to the remaining 90% as if the difference did not matter.
The difference did matter. The capital, the interest, or the intent had not arrived. To bridge this, a small group came together in 2019 at IIT Madras.
AI4Bharat began as an unfashionable bet. India could not wait for English-first AI systems to accidentally become good at Indian languages. It focused on the boring but essential work of building datasets, benchmarks, tokenisers, and models for Indian languages. It would be the plumbing without which no Indian-language AI company could be built.
A co-founder of AI4Bharat was a deeply technical researcher at Microsoft. Pratyush Kumar was leading AI4Bharat’s Indian-language build alongside Mitesh Khapra, an IIT Madras researcher, and Anoop Kunchukuttan, another researcher at Microsoft. Vivek Raghavan continued his population-scale work at UIDAI, the Aadhaar-enabling body.
These two India first, large scale groups were about to get enmeshed.
The GPT That Changed the Question
In 2020, AI4Bharat published IndicBERT, a multilingual model covering 12 Indian languages trained on the largest Indic corpus assembled to that point.
The benchmark that followed, IndicXTREME, was a nine-task evaluation suite covering 20 Indian languages and the first rigorous comparison of how AI models performed in Indic languages versus English.
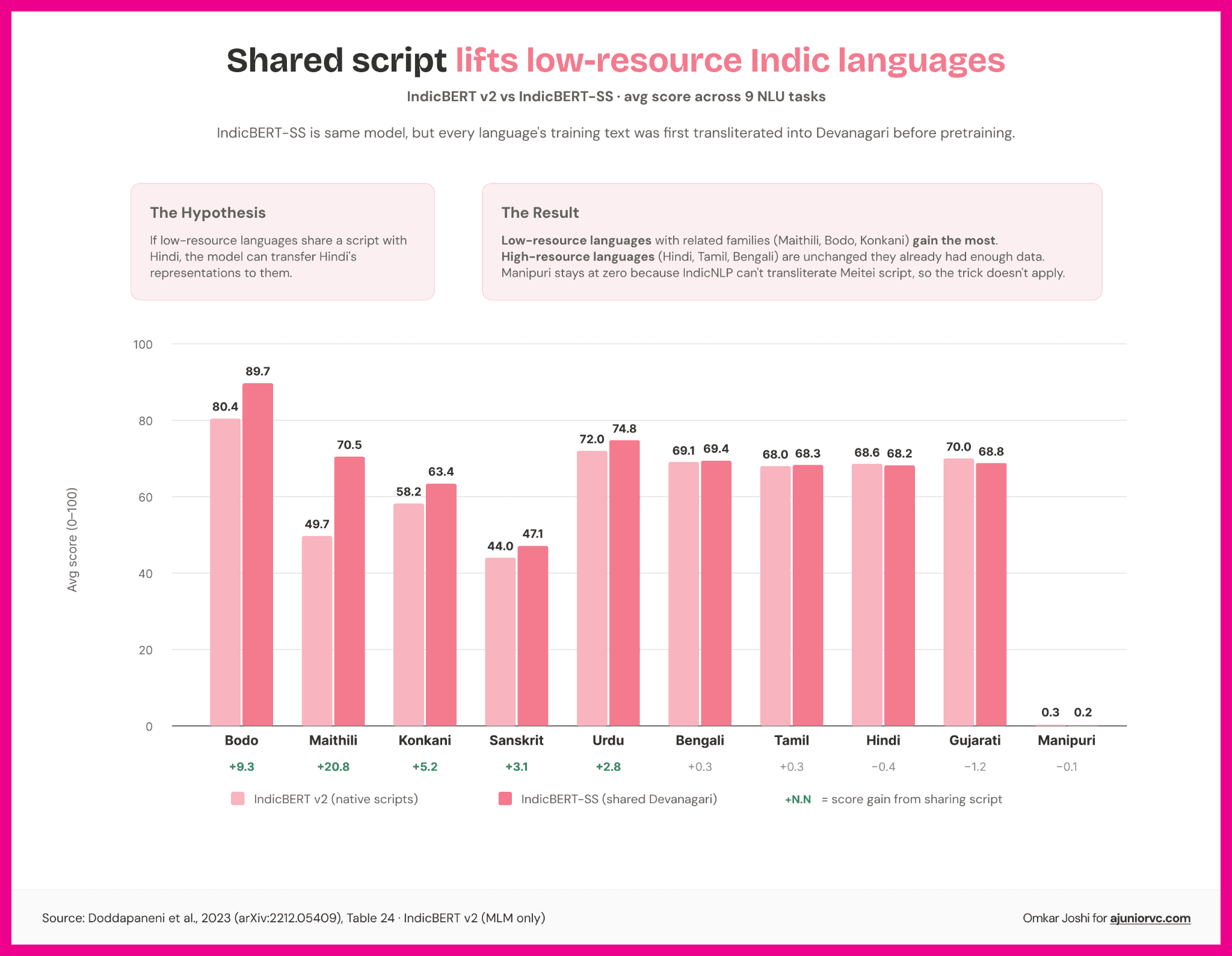
The number was damning. Indian languages performed three to four times worse than English on standard benchmarks. The gap was structural, baked into the architecture of every major model worldwide because of how those models had been trained.
Tokenisers decide how language is broken into units before a model processes it. A sentence that takes 10 tokens in English may take 30 or 40 tokens in an Indian language on an English-first tokeniser. More tokens mean higher compute cost, slower inference, and more expensive products. For India, where the opportunity is population-scale but price-sensitive, token efficiency was the business model.
Kumar had shown that Indian languages underperformed, why they underperformed, and why the fix would require work at the foundation layer. It needed a build, from scratch.
The research world published the findings. The investing world was busy calculating the lifetime value of an English-speaking user in California.
Then, on November 30, 2022, OpenAI released ChatGPT. The storm unleashed by reaching 1 million users in days was not going to stop soon. Before ChatGPT, the underperformance of Indic languages was a research problem. After ChatGPT, it became a market problem. If natural language was going to become the interface to software, then the quality of Indian-language AI was no longer an academic deficit. It was a national access problem.
The question the tech world had been asking was whether AI could hold a natural conversation. ChatGPT answered yes and moved on. The question that replaced it was simpler and more uncomfortable: for whom?
Every VC in India started asking the same thing around the same time. Who is building this for India? The answer was: nobody well-funded. There were fine-tuning projects and API wrappers. There was no well-capitalised lab training base models on Indian data. The gap AI4Bharat had spent years measuring had suddenly become a market.
By 2023, four things had changed at once: India had hundreds of millions of vernacular internet users; Aadhaar and UPI had normalised population-scale digital infrastructure; voice was emerging as the natural interface for non-English-first users; and large language models had made language itself the interface to software. The timing was not a coincidence.
Kumar left IIT Madras. Raghavan walked away from his advisory work. In August 2023, less than a year before GPT’s launch, they came together to found Sarvam, the Sanskrit word for everything. Sarvam wanted to create foundational AI for India. Four months later, they raised a $41 million in Series A, valuing the company at $110 million.
For a company with no product, that was a vote of confidence that says more about the size of the gap than the size of anything Sarvam had built yet. It had to build a lot.
Sovereign on Paper
The $41 million did not go into a marketing budget.
A note on what "sovereign AI" means here, because the term is often used and defined rarely. Sovereign AI does not mean an Indian company building an AI model. It meant control over the data, compute, tokeniser, architecture, deployment environment, and cost structure through which intelligence reaches Indian users. Each of those components mattered. Giving up any one of them created a compounding dependency.
In January 2024, Sarvam released OpenHathi, their first public model. It was a 7-billion-parameter Hindi language model built by extending LLaMA 2 with a large corpus of Hindi text. Compared to GPT’s 1 trillion parameters, it was a pygmy. Think of parameters as weights and biases in a model, or those values to be tweaked so that the model gave the right answer. A larger parameter model tended to be better.
Yet, on standard Hindi benchmarks, Hathi outperformed every publicly available model at its parameter size. The AI research community went through it carefully. The general tech press barely noticed. That suited Sarvam fine.
What OpenHathi also proved was something the benchmarks did not fully capture. Indians do not speak in clean Hindi or clean English. They speak in a fluid mix of both, switching mid-sentence, sometimes mid-word, in a way that trips every model trained on one language at a time. "Kal meeting mein I have to present the Q3 results" is not broken Hindi. It is how a hundred million Indians talk to each other every day. OpenHathi handled it. Every other model treated it like an error. Developers building for Indian users noticed the difference immediately.
The rest of the stack came across 2024. Shuka for speech recognition, turning spoken Indian language audio into text with a word error rate that undercut OpenAI's Whisper on Indian languages and accents. Bulbul for text-to-speech, generating voice output in Indic languages that sounded like a person rather than a GPS giving directions. Mayura for translation, moving between Indian languages without routing everything through English first, which is how every competing translation system worked and also why every competing translation system lost half the meaning along the way. Each is released as an API. Each aimed at developers and enterprises, not end users.
Sarvam was building the stack underneath the apps, not the apps themselves. UPI does not have users. PhonePe, GPay and Paytm have users. UPI has builders. Sarvam wanted to be the UPI of Indic AI: invisible to most people, indispensable to every product built on top of it.
In March 2024, the Union Cabinet approved a new mission focused on AI. The IndiaAI Mission had an outlay of ₹10,371 crore.
The important part was not the announcement itself, but what it chose to fund: compute capacity, datasets, foundation models, application development, startup financing, skills, and safety.
For Indian AI companies, compute was the constraint. Without access to GPUs, even the best teams would remain dependent on foreign APIs or small fine-tunes of foreign models. The IndiaAI Mission changed the backdrop.
It did not create Sarvam’s thesis, but it made the thesis legible to the state: if India wanted AI systems that worked in Indian languages, on Indian use cases, at Indian price points, it would need domestic model-building capacity.
The Wrapper Trap
By October 2024, Sarvam-1 arrived.
A stronger 7-billion parameter model, with better handling of code-switched text than anything at its size. The technical report was detailed enough that researchers could evaluate it properly. Hugging Face downloads trickled in. Enterprise conversations progressed. Government conversations progressed faster than anyone outside the room knew.
For Raghavan, this was familiar terrain. Aadhaar had also looked impossible before it became an invisible public infrastructure. For Kumar, the moment was different but connected; the language gap he had spent years measuring was being treated as a market.
In April 2025, the IndiaAI Mission selected Sarvam to build India's domestic large language model, the first arrangement of its kind where the government would provide dedicated compute infrastructure and take an equity stake in return. The government of India was writing a two-year-old startup into the country's AI strategy as its primary institutional bet. When a startup and a government share the same cap table, they share the same incentive to make the thing work.
The same month, UIDAI announced a partnership with Sarvam to bring AI-powered voice interaction and multilingual support to Aadhaar services. A custom AI stack, built to run within UIDAI's secure on-premise infrastructure, supporting ten Indian languages with real-time enrolment feedback and fraud detection. On-premises means Sarvam's models run on UIDAI's own servers, under UIDAI's own security protocols, handling data belonging to a billion Indian citizens.
Once a model is embedded inside sensitive public infrastructure, the switching cost is no longer just technical. It involves data control, compliance, trust, procurement risk, and institutional continuity. The man who had spent twelve years building Aadhaar's biometric foundation for free was now building its AI brain for equity. The parallels were right there.
It was the right positioning — right up until the market decided institutional credibility alone was not enough. In early 2025, Sarvam began building its first model for public release.
The tension was narrative. Sarvam-M, as it would be called, was a 24-billion-parameter model fine-tuned for Indian languages, with solid performance on Indic reasoning and multilingual tasks. The Indic-specific work was measurable, and the team had pushed the frontier on what Indian-language AI could do. But underneath it ran Mistral Small, a French open-source model, as its foundation.
Fine-tuning existing models is standard practice across the industry. Almost every enterprise AI product does it. The technical decision was defensible. The narrative problem was sovereignty. When your brand promise is "built from scratch for India," your configuration file becomes a document of credibility.
The model was nearly ready. The public test was coming faster.
Three Hundred and Thirty-Four
On May 23, 2025, Sarvam released Sarvam-M.
In two days, it got 334 downloads on Hugging Face. That same week, a model built by two Korean college students got 200,000.
Sarvam-M was written off as an extremely expensive gimmick. Critics dissected the configuration files, found the Mistral base, and the wrapper accusation that had been hovering over Indian AI for months landed on Sarvam's doorstep.
The 334 downloads did not prove Sarvam had failed. But they proved the company had not yet created a public developer pull. For a company positioning itself as the foundation for Indian AI, that perception mattered. Sarvam-M deserved the scrutiny. A company claiming sovereignty had released a model built on a foreign foundation. That did not make the work fake, but it made the positioning vulnerable.
The criticism captured a real weakness: Sarvam's public model did not align with its sovereign positioning. It also missed another reality: the company's deeper institutional work was already running outside public benchmarks. 334 Hugging Face downloads and a billion Aadhaar users are not the same metric.
Sridhar Vembu, one of India's most credible technology voices, stepped in with one line: "No product was ever an instant hit." It did not stop the criticism. But it named what the critics were doing, judging a twelve-year research career and a two-year company by a single day's download count.
The founders did not respond publicly. They went back to work, like they usually did. Yet a storm had been brewing for a national model in an entirely different country.
Sarvam was ready to take inspiration.
Back to the Drawing Board
In January 2025, just before Sarvam’s launch, a lab called DeepSeek released R1 and briefly wiped $600 billion off Nvidia's market cap in a single session.
DeepSeek mattered to Sarvam less as a Chinese success story and more as a proof of method. It showed that a focused lab outside Silicon Valley could build credible models by being disciplined about data, architecture, and cost before the first GPU was switched on. Not through more funding. Through a smarter approach applied earlier.
The decision that followed looks obvious in retrospect and required real conviction in the moment: scrap the fine-tuned approach, go back to zero, and train base models on Indian data and Indian soil.
From the outside, nine months of rebuilding looked like silence. For a company that had been publicly criticised and needed to rebuild credibility fast, the absence was conspicuous. Inside, the work had moved to the foundation: data, tokeniser, corpus, compute, architecture. Training from scratch means building the pre-training corpus before anything else, which for Sarvam meant sourcing Prasar Bharati archives, government document repositories, regional newspapers across twenty-two languages, legal databases, digitised books, filtered web crawls, and then cleaning and assembling all of it into something a model can learn from. You build the data before you train. You build the tokeniser before the data is ready to use. None of this produces a demo. It produces a foundation.
Another startup, backed by a founder who has won in duopolistic situations, jumped in
Krutrim AI took a louder, more consumer-facing path. Sarvam took a quieter, infrastructure-first one. The difference matters because Indic AI is less a branding problem than a data, language, and deployment problem. While it looked like a challenger for a while, it began to struggle by the wayside. Three rounds of layoffs at Krutrim by late 2025 targeted its linguistics team, the people responsible for sourcing, curating, and cleaning training data for Indian languages.
The founders of Sarvam said nothing about any of this. They were nine months deep into building something they could not yet show anyone.
Trained From Scratch
On February 18, 2026, almost 10 months after the launch, at the AI Impact Summit at Bharat Mandapam in New Delhi, Sarvam walked on stage and settled the argument.
Sarvam-30B and Sarvam-105B. Both trained from scratch on a domestic computer provided under the IndiaAI Mission. Both were open-sourced on the same day they were announced, straight to Hugging Face with no waiting list. The 105B model uses a mixture-of-experts architecture — 105 billion total parameters, but only around 10 billion active at any given moment — which makes it possible to deploy at scale without requiring a data center the size of a small town. According to Sarvam's published benchmarks, both models outperform leading global systems on several Indic OCR, speech recognition, and voice-agent tasks, as well as on general reasoning.
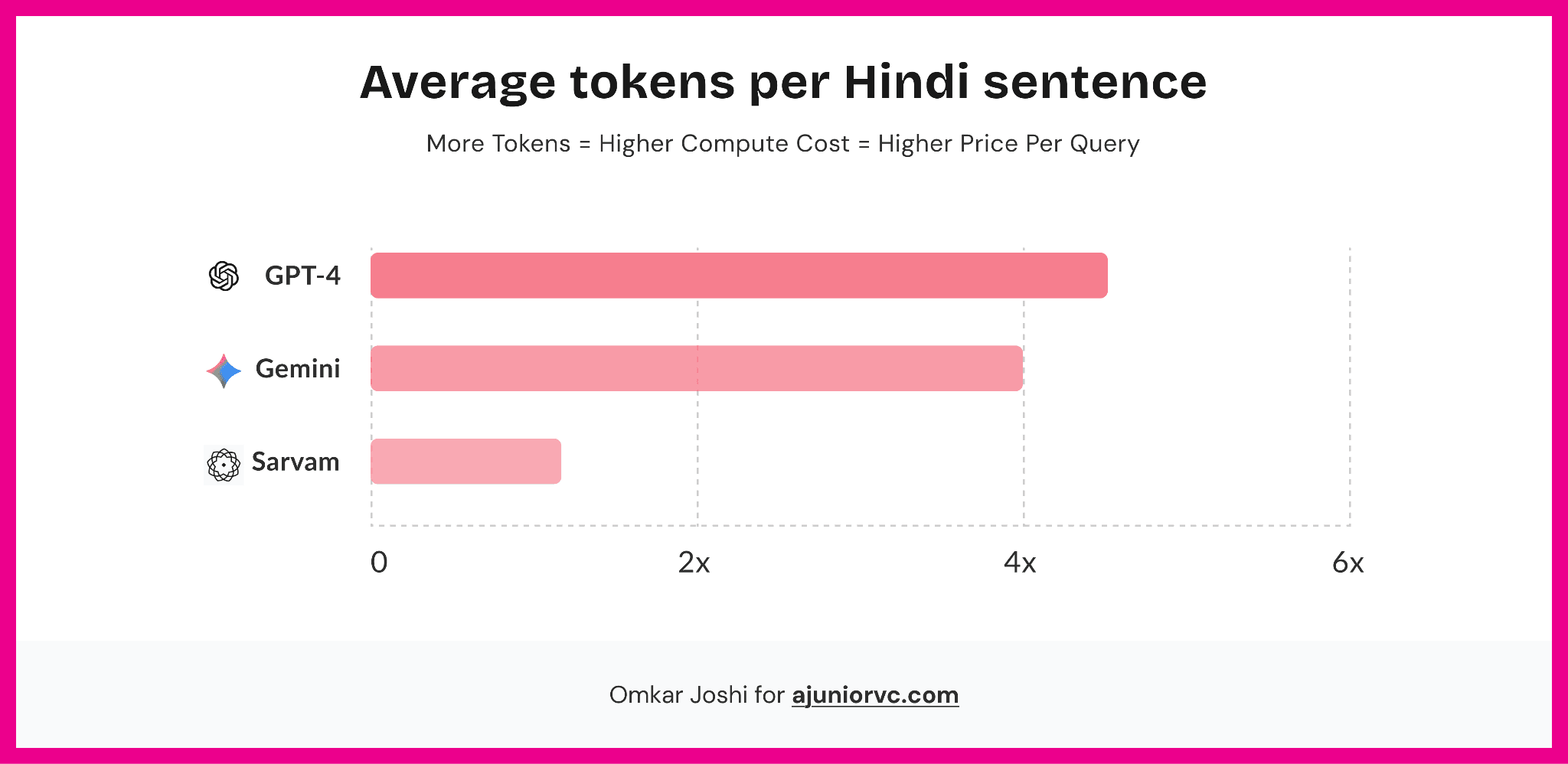
This tokeniser advantage is where the economics converge.
Sarvam's Indic-optimised tokeniser processes Indian language content three to four times more efficiently than foreign models. Fewer tokens per sentence means lower compute cost per query, and at the population scale Sarvam is targeting, that gap is not a benchmark number. It is the difference between AI that works at India's price points and AI that prices itself out of the reach of the billion users it claims to serve.
On February 20, Sarvam released Indus, the consumer-facing beta of Sarvam-105B, on iOS, Android, and the web. According to the company, Indus crossed 50,000 downloads in its first week.
The products kept coming fast. In March 2026, the Sarvam Startup Program launched, giving selected early-stage Indian companies six to twelve months of API credits, priority engineering support, and access to production infrastructure. The strategy is to become the AI stack that Indian builders default to, and the startup program is how that strategy compounds. You put your APIs into the hands of the next generation of founders before they ever think to open OpenAI's pricing page.
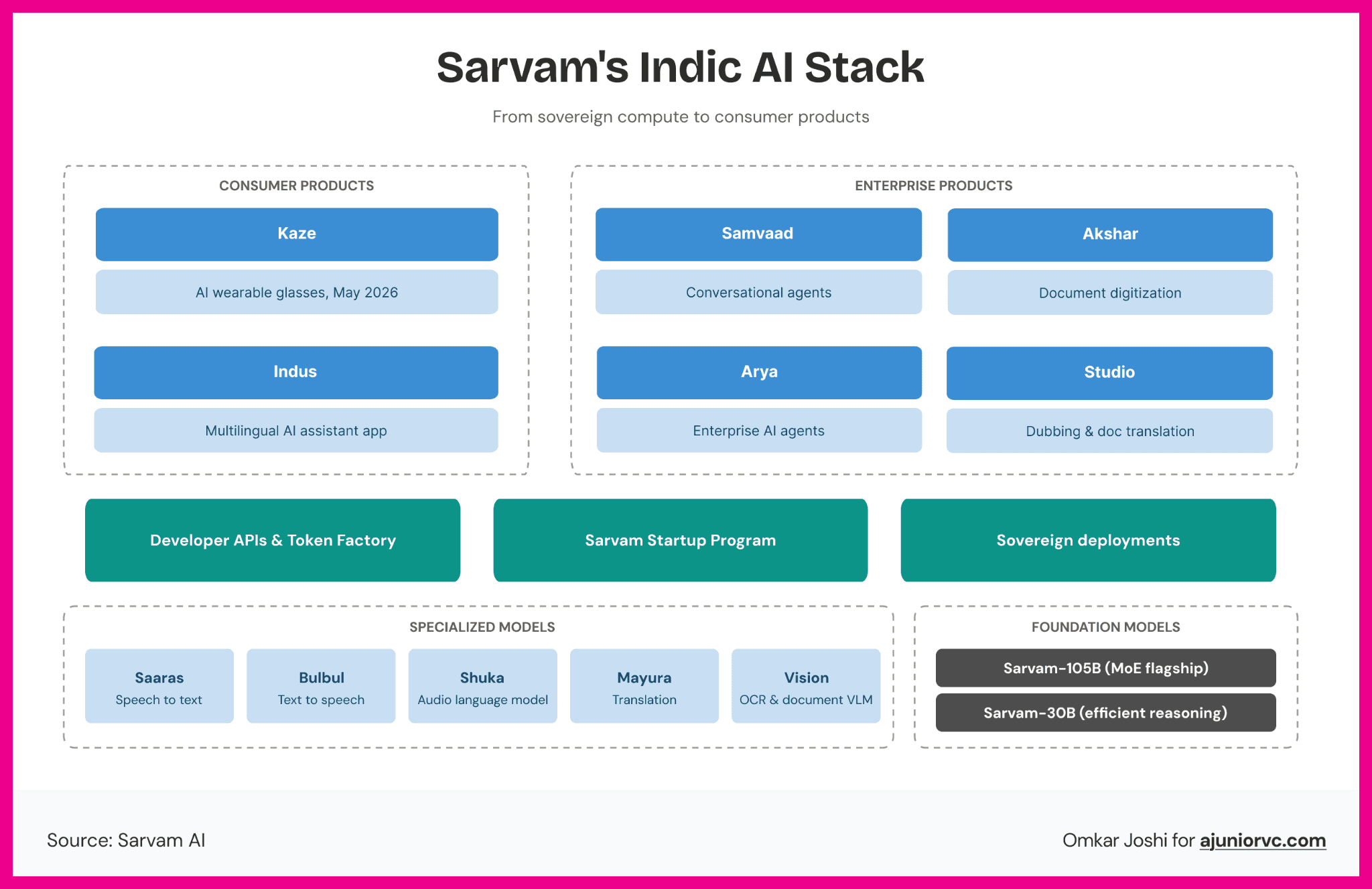
The government infrastructure work has been building underneath all of this.
Reported state partnerships include Odisha's proposed 50-megawatt AI-optimised hub, with Sarvam as the AI layer supporting mining, industrial safety, and Odia-language skilling, and Tamil Nadu and IIT Madras's Digital Sangam, anchored by a 20-megawatt data centre. Each one is more than just a revenue contract. Government deployments, if they go deep enough, create trust, compliance familiarity, on-premise integration, procurement history, and switching costs that a benchmark improvement alone may not displace. The deployment depth is the institutional advantage — not the relationship.
Krutrim was not at Bharat Mandapam. India's most buzzy AI startup missed the year's biggest AI showcase. Its absence was notable. Eleven months is a short time to go from being dismissed as a wrapper to being treated as India's most credible domestic AI bet.
Sarvam Means Everything
Can Sarvam AI build the intelligence India actually speaks?
Start with the competitive landscape, because "India's AI race" is a phrase that gets used loosely and is usually imprecise.
The story is less about which company wins and more about which strategy holds. Bhashini, the government's National Language Translation Mission, matters as public infrastructure but operates at the government's pace. BharatGen, the academic consortium at IIT Bombay, does credible research but is not a product company. Gnani AI builds strong enterprise voice AI in Indic languages - a different slice of the same large problem. The field is less a race and more a set of parallel bets on different parts of the same challenge. Sarvam is the only one attempting the full stack: from base models to APIs, consumer interfaces, and public infrastructure.
The global players represent a different kind of constraint, and the reason is architectural.
A base model is trained from scratch on billions of raw tokens, with architectural decisions made before training begins. Everything above that, every fine-tuned assistant, every API wrapper, every consumer product is downstream of those original decisions. If the model was built on predominantly English data with an English tokeniser, everything above it carries that bias. Fine-tuning will move benchmark scores. It will not move the tokeniser. The architecture is the constraint you carry forward.
OpenAI and Google can improve Indic performance, and likely will. Gemini has made genuine progress on Hindi. But their core architectures were not designed with Indian-language economics in mind from the beginning. This is not the kind of problem that disappears through a product update. Fixing it means going back to the beginning and rebuilding the foundation. Sarvam has done that. The global labs have not.
The government contracts are where this advantage compounds into something structural. Every state that deploys Sarvam's models is a proof point for the next state. Every government vertical running on Sarvam is a system that the next procurement tender must displace, not compete with. The moat is not model quality alone. It is deployment depth, trust, compliance, familiarity, procurement history, and institutional continuity.
The DeepSeek comparison helps identify a focused lab outside Silicon Valley, training from scratch on its own infrastructure, optimised for its own context, that can produce a world-class model at a cost that changes what people believe is possible. China had been building toward that outcome for years. DeepSeek was confirmation. India now has its own version of that story in motion with a company that has the government, the compute, the research pedigree, and the open-source credibility to make it legible to the world.
The business model is likely to compound across four layers: developer APIs, enterprise deployments, government and on-premise systems, and startup ecosystem adoption through credits and support. If Sarvam becomes the default stack for Indian-language AI applications, revenue will not come from a single killer app. It comes from usage across many.
At ₹29.1 crore of reported revenue and a $1.5 billion valuation, Sarvam is not being valued like a normal software company. It is being valued like infrastructure. The multiple is not pricing what exists today. It is pricing the possibility that Sarvam becomes the default intelligence layer for Indian government, enterprise, and consumer applications.
The risk is real and worth naming.
Sarvam still has to convert technical credibility into durable revenue, developer adoption, enterprise retention, and model quality that stays ahead of both Indian competitors and global labs, improving quickly. The valuation gap closes only if the institutional bets compound into a platform.
India has built population-scale digital infrastructure before and has been underestimated every time. Aadhaar enrolled a billion people when the consensus said the scale was impossible. UPI now processes 18 billion transactions a month and has been adopted by other countries as a model. Each time, the pattern was the same: a focused bet, a willingness to build rather than import, and enough patience for the compounding to become visible.
Vivek Raghavan volunteered for twelve years because he believed India needed the infrastructure, and nobody else was going to build it. Pratyush Kumar spent years at a non-profit measuring a gap the market had decided was too small to matter. The backlash, when it came, was fast and loud. The rebuild took eleven months and started from scratch. The funding validates the bet, but it only poses the question. India built identity rails. Then it built payment rails.
Sarvam is now trying to build intelligence rails for a country whose people do not speak, type, or think in one language.